The need to organise knowledge for retrieval is a fundamental requirement for scholarship. Jacob (1997) describes a number of different approaches used by Alexandrians to organise knowledge,
such as compilations, catalogues, and philosophical doxographies. Ordering principles include geographical, bibliographic, thematic, and chronological. Collections are based on the notion of indefinite expansion, whereas other projects, such as those based on cartography, history or geography, aim to create a new form of unified knowledge at a higher level of abstraction.
The discipline that built up around identifying and retrieving scholarly and technical knowledge became known as information science134.
The invention and spread of printing of course greatly facilitated the dissemination of scholarly information. However, as argued above, the needs of technical, academic and scientific research and publishing are not well met by books and library catalogs that are respectively often too far removed from the original research which generates knowledge, and too coarse–grained to retrieve the kind of detailed knowledge researchers need. This was already recognized with the beginnings of the Scientific Revolution in the latter half of the Seventeenth Century, with the development of the first learned societies, such as the Royal Society (of London) – founded in 1660 and the Académie des Sciences (in Paris) – founded in 1666. The first scientific journal, Journal des Sçavans, was published in 1665135, followed within the year by Transactions of the Royal Society and Académie des Sciences, respectively (Fjällbrant 1996).
Once the idea of publishing journals on specialized topics took hold, "Scientific" knowledge based on direct observation and experiment began to grow rapidly, and soon differentiated into "primary" and "secondary" literature.136 Primary literature consists of the reports of original research, and has grown to the extent that for many disciplines it is beyond the capacity of any one person to read more than a tiny fraction of what is published in his/her own discipline – let alone science as a whole. Even the early scientific journals included the concept of articles reviewing and summarizing literature published elsewhere. This secondary literature evolved to include subject related indexes, abstracts, review articles, textbooks, and bibliographies that attempt to summaries and point to original work in particular disciplines of knowledge. In a sense, the secondary literature fills a comparable role for science and scholarly journal articles that indexing and cataloging does for a library of single topic books.
An early attempt to provide a global index of all articles published by scholarly societies (i.e., comparable to a universal catalog) was the Reuss Repertorium, published from 1801–1821.137 This was followed by the Royal Society of London's Catalogue of Scientific Papers, published from 1867 to 1925.138 As scientific and scholarly publishing grew to overwhelming volumes, this kind of global indexing became increasingly difficult to achieve with purely manual means.
Given the difficulties inherent in indexing everything in the one place, more specialized bibliographic services evolved to catalog, index and abstract the literature of particular disciplines. The disciplines involved in developing such indexing services and related technologies became known as information science. A comprehensive chronology of the development of information science, along with a list of source references is provided by Williams (2001). Following are highlights some of the earlier services (with their establishment dates) that are now accessible over the Web (in most cases only by subscription).
Apparently the oldest of the surviving specialized services (and one of the first I used professionally) is the Zoological Record, first published in 1865.139
These were followed by
Index Medicus, established by the polymath John Shaw Billings140 in 1879 (Zipser 1998; Schulman 2000), was the direct ancestor of the US National Library of Medicine's free to the Web search service, PubMed;
Science Abstracts (Physics and electrics, from 1889 – now published as Physics Abstracts, Electrical & Electronics Abstracts and Computer & Control Abstracts) – available electronically as INSPEC;141
Chemical Abstracts (from 1907);142
Biological Abstracts (from 1926)143, where I first learned the incredible retrieval power of computerized indexes and Boolean search and retrieval
Science Citation Index (from 1961)144.
Legal citation indexing (Liebert 1999; Shapiro 1998; Taylor 2000) was another specialized service that developed early, with the oldest and most familiar being Shepard's, which traces back to 1873.
Before computerization, these indexes were extremely labor intensive and costly to produce. People had to read articles, then abstract, classify, and prepare index entries, and then compile the result into a publishable format. As will be discussed in more detail below, computerization facilitated classification, indexing and compilation – with most services computerizing their indexing activities to some degree and providing computer searchable products (via magnetic tape or online) in the 1960s and 1970s. Now, the increasing use of semantic markup languages such as SGML and XML in the Scientific, scholarly and professional journals are enabling these kinds of indexing services to be produced automatically from the original articles with little or no human intervention.
Scientific, scholarly and professional publishing grew exponentially after the end of the Second World War along with growing populations of academics and academically trained professionals who needed access to the specialized literature (Walker, 1998). This involved the publication of more journals and more papers in each journal that would benefit from indexing to aid their retrieval. Beginning in the mid 1950's and with the development of the digital computer being fuelled by Moore's Law, more and more aspects of the indexing, query and retrieval processes could moved into a computerized environment with the development of databases for particular bodies of knowledge. The first on–line systems providing access to single databases were established in the late 1960's (Williams 2001).
The basic idea of a computerized bibliographic database is the same as that of a library catalog. Indexes are created for each separate kind of information about articles held in the database. Terms in each index are arrayed in alphabetic or numeric order so the query process "knows" where to start looking. A hit on a search term in the index then links to a complete bibliographic record detailing the article – or with increasing frequency, to the whole article itself. For example, the title index will list all words (exclusive of "stop" words) used in the titles of all articles included in the database.
The computerization of single bibliographic databases was followed in the early 1970's by on–line services that provided single access points to aggregated collections of bibliographic indexes. Of the surviving commercial services, the first two, both open to the public in 1972 were Lockheed's Dialog145 and Systems Development Corporation's ORBIT146.
Even with bibliographic indexing limited to narrow disciplines, the indexing services are epistemically valuable only if end users can locate source documents containing the desired knowledge with a reasonable effort. Basically, the power of an index and its search engines is determined by how well the contained data can be queried and retrieved in ways that will be semantically meaningful to its human users. Hahn (1998) lists a number of functions bibliographic index systems provide for finding sources of knowledge. Most were first introduced in the mid 1960’s. Here, I note the most important ones and indicate how the function works to provide the semantic connection.
Boolean logic (AND, OR, NOT)
Boolean searching is one of the most useful functions provided by modern bibliographic databases, in that it allows users to describe the knowledge sought in a way that is also semantically meaningful to a computer system. Boolean logic allows users to construct reasonably sophisticated search expressions using the AND, OR, and NOT operators
Most bibliographic database systems allow Boolean operators to be combined or nested using parentheses to make sophisticated search expressions. Even without other tools, these simple retrieval tools allow a user to substantially filter the likely responses to a reasonable practical number of hits that would be worth exploring further.
Citation indexing is potentially much more powerful semantically than Boolean searching, and is based on a completely different logic inherent in the way that knowledge grows and is aggregated from observations, prior knowledge, and testing. Used originally in manually created legal indexes, computers were first applied to bibliographic databases of scientific and academic literature by Eugene Garfield's ISI147. The power of the retrieval methodology depends on the original authors' formation of semantic links between the articles they publish and articles they reference in assembling the knowledge recorded in their publication148.
An author adds a citation to a bibliography or footnote because he/she referred to some relevant information in the cited article. The citation index database is built by extracting citations from a list of papers, and then indexing the original articles by the articles they cite. Thus, a user who is familiar with the literature of the discipline being searched can select one or more relevant papers representing the kind of knowledge being sought, and then go to the index to retrieve details of any more recent articles articles citing that kind of knowledge. The inference is that at least some of the content of the citing paper will derive semantically from the cited papers. The reference to a cited paper may be trivial, but there will at least be some valid semantic connection between the citing paper retrieved and cited paper used as a search term. The bibliography of the more recent citing paper may then be used to select citations to possibly more directly relevant older papers that may be used as additional search terms to generate new lists of more recent citing papers. This contrasts with Boolean and other related search methods that depend only on the occurrence of particular words in a single document – which often retrieve a high frequency of completely irrelevant material.
Citation indexing thus establishes both ends of two-way semantic links between source documents and their derivatives, to build a contextual web of assimilated information and knowledge that exists in World 3, completely independent from any knowing person..
stemming or truncation by wildcards (?, *, ...)
These are different methods allowing a part of a word to be used for a search term (e.g., search on the root "enter" for enter, enters, entering, entry, entered, etc.). The "?" operator accepts any single character at the point of the question mark. The "*" operator accepts any combination of characters up to or following the characters actually specified in the search term, depending on whether the asterisk begins or ends the search term. The ELIPSIS operator ("...") may be used in some systems to match all characters occurring between particular beginning and ending characters. Simple wildcard systems will pick up unrelated concepts where the sequence of characters in the root is the same. These operator concepts were first developed in the mid 1950's with the development of "regular expressions", which could be used to identify Boolean matches on a character–by–character basis. Some of the more sophisticated stemming processes will search on all of the parts of speech for a specified term even where the root is spelled differently for some of them. This kind of methodology allows a broader search on a concept not confused by spelling differences introduced by grammar.
Proximity operatiors (NEAR)
First used in 1969, and with details depending on the particular search application, NEAR operators allow Boolean operators to be applied within a sentence, a paragraph; or within a certain number of words, sentences or paragraphs of one another. The concept here is that the search terms are likely to be semantically connected to one another if they occur close together.
Ranking and relevance
Listing hits in assumed order of importance relevant to the query.
Contexts or zoning
Highlights search terms in displayed text snippets to help users determine whether the article is likely to be worth retrieving.
Results set iterations
Users can refine searches by searching on additional terms within a larger set of records returned by a prior search.
Full document retrieval
For many of the early systems it was economically impossible to store full documents online. However, an increasing number of bibliographic services did offer some provision for delivering hard copy of selected references at great cost, e.g., via "tear sheets" where pages might be physically torn out of the journals in question or via manual photocopying.
World–wide access
The ability to access servers in one country from another country half way around the world was first demonstrated in 1967.
Each of these indexing technologies gave sophisticated users additional powers to retrieve bibliographic entries likely to be relevant to their needs. However, many of the features depended critically on up–front activities to have humans actually read the articles to create meaningful index items in the bibliographic records. Because of this labor requirement, such systems were expensive to deploy commercially and cannot be economically provided to the public for free. Also, even when all of the features could be used together, the computer systems were unable to understand enough of the document structure to provide any real help. For many users, the only way to achieve a practical benefit from these capabilities was to work through expensively trained librarians and information scientists, which increased retrieval costs still further. As will be seen in Episode 3, new technologies and new ways of structuring documents are radically changing this equation.
Even with electronic indexing tools to help people locate the knowledge sought, the growth of the literature is putting research libraries under increasing stress. More journals are published every year, and individual journals are becoming increasingly expensive (Walker 1997; Odlyzko 1994).
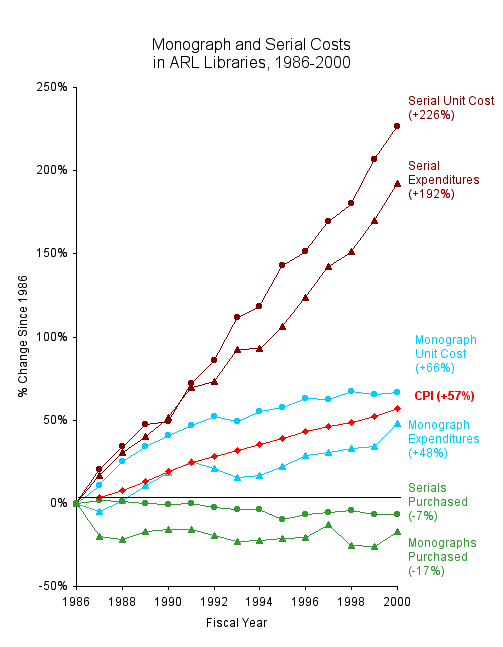
It is becoming prohibitively expensive for even the largest research libraries to maintain complete collections of the literature (Solomon 1999). In the 25 years from 1970 to 1995 the cost of journal subscriptions increased by some 18 times compared to an increase of approximately 4 times for books and monographs (Walker 1998). The Association of Research Libraries’ Annual Statistics Reports also make this painfully clear (e.g., Kryllidou 1999, 2000; Case 2001), as illustrated in the Figure.
Figure 14. Escalating library costs (from Case 2001)
The current system of scholarly publishing has become too costly for the academic community to sustain. The increasing volume and costs of scholarly publications, particularly in science, technology, and medicine (STM), are making it impossible for libraries and their institutions to support the collection needs of their current and future faculty and students. (Case, 2000)
Paper journals are also very costly to publish and distribute. Odlyzko (1999) estimates that the average journal article costs $4,000149 to produce (in terms of publisher's revenue per journal divided by the number of articles published in the journal), plus another $8,000 in libraries' administrative and running costs amortized per article, plus $4,000 in editorial and referee costs (in many cases borne by the individuals doing the work) and another $20,000 author's costs to prepare the article. Thus, with paper technology, a single article, on average, costs something on the order of $36,000 to produce150). This does not include the indexing services' costs to reference the article in their indexes.
Thus, the cost to record and access knowledge via journals and libraries has become a significant fraction of the cost of doing research. For some libraries – especially those in less well developed countries – comprehensive journal holdings have become an expensive luxury they simply cannot afford. Every year, most libraries face the question – not what new things they should add to their collections but rather what acquisitions and journal subscriptions they must cancel so they can still stay within budget (Krillidou 1999; Russo 2001; Day 1997). And for those like myself, who until recently have lacked ready access to high quality research libraries, reasonable access to physical copies of specialist journals is close to impossible. My budget only allows personal subscriptions to a very few general journals such as Science and Nature.
However, with an increasing number of journals being distributed electronically to libraries, and the libraries offering electronic access to these journals to their communities via portals (Wetzel 2002) and increasing signs of revolt by libraries and their users (Suber 2002), the economics of journal publishing and distribution may be beginning to change.
The other major issue relating to dissemination of knowledge via journal publication has been the long lag between the author's completion of a paper and its availability in a journal to those who need the information. This often costs one to two years or more where paper journals are concerned, and has led to a proliferation of informal means of publication via conferences and pre–prints. These add additional costs to the dissemination and use of knowledge over and above the costs of formal publication summarized above.
The bottom line is that the cost of publishing scientific and technical information to paper journals has escalated to the extent that there is a major demand from users, libraries and the increasingly non–competitive publishers themselves for better and less costly mechanisms to record, store and retrieve core knowledge (Walker 1997; Day 1997; Varmus 1999; Butler and Wadman 1999; Marshall 1999; Russo 2001)151. How these issues are likely to be resolved will be discussed in my Cadenza
Compared to the library–related bibliographic cataloging and indexing technologies discussed above, which have been developed over more than a century, cognitive retrieval and linking tools for personal desk–top use have evolved from essentially nothing in less than 15 years, with the most pervasive one being the World Wide Web. Beginning with the launch of Mosaic in 1994, the Web has exploded in less than a decade from an idea into a system used to access a reasonable sample of humanity's total knowledge by a significant fraction of humanity in the world's developed countries.
As is often the case with revolutions, it has been necessary to invent a whole new vocabulary to describe and explain how these new technologies work. Good definitions for the new terms are essential if discussions are to mean the same thing to everyone involved. In the following, essential terms are hyperlinked to TechTarget.com Inc's (2000) What?is.Com.